AWS Analytics Advent Calendar 2022 の 20 日目のエントリーです。
Amazon Redshift のシステムテーブル・ビューからデータドリブンで遅いクエリのボトルネック(どこに時間がかかっているか)を分析する方法を紹介します。
クエリを実行して情報を収集する
- yoheia/aws/redshift/redshift_measuring_query_exec_time at master · yoheia/yoheia · GitHub
- psql での実行を想定
-- 現在時刻を取得する select getdate(); -- 実行時間の計測を有効にする \timing on -- pager を OFF にする \pset pager off -- Redshift のリザルトキャッシュを無効化する set enable_result_cache_for_session=off; -- 計測対象クエリを実行する \i lineorder_count.sql -- 実行したクエリのクエリIDを取得する(:pg_last_query_id でクエリIDを取得できる) -- CTAS の場合の書き方を追記予定 select pg_last_query_id(); \gset -- 以降でシステムテーブル・ビューから性能情報を取得する select userid, trim(database) "database", trim(label) as label, query, xid, pid, datediff(milliseconds, starttime, endtime) as "exec_time(ms)", starttime, endtime, aborted, insert_pristine, concurrency_scaling_status, trim(querytxt) as query_text from STL_QUERY where query = :pg_last_query_id; /* psql でない場合 -- クエリID を一時表に保存 select pg_last_query_id() as qid into temp table qid_tmp; -- 一時表からクエリIDを取得 select userid, trim(database) "database", trim(label) as label, query, xid, pid, datediff(milliseconds, starttime, endtime) as "exec_time(ms)", starttime, endtime, aborted, insert_pristine, concurrency_scaling_status, trim(querytxt) as query_text from STL_QUERY where query = (select qid from qid_tmp); */ (以下略)
前提知識
クエリ実行の流れ
- ユーザークエリはリーダーノードで rewrite されて複数の子クエリに分割されて実行されることがある。
- リーダーノードで C++ のコードに変換後、コンパイルされセグメント単位でオブジェクトファイルになる。
- クエリのコンパイルキャッシュはセグメント単位でキャッシュされる。つまり、クエリ全体で同じではなくても、セグメント単位でキャッシュがあれば再利用される。Amazon Redshift のバージョンが上がると、再コンパイルされる(旧バージョンのコンパイルキャッシュは再利用されない)。
- コンパイルキャッシュは CaaS(Compilation-as-a-Service)でキャッシュされるため、クラスターを再起動しても消えない。
- セグメントは並行実行されることがあるが、ストリームはシリアル実行される。
ボトルネックを分析する
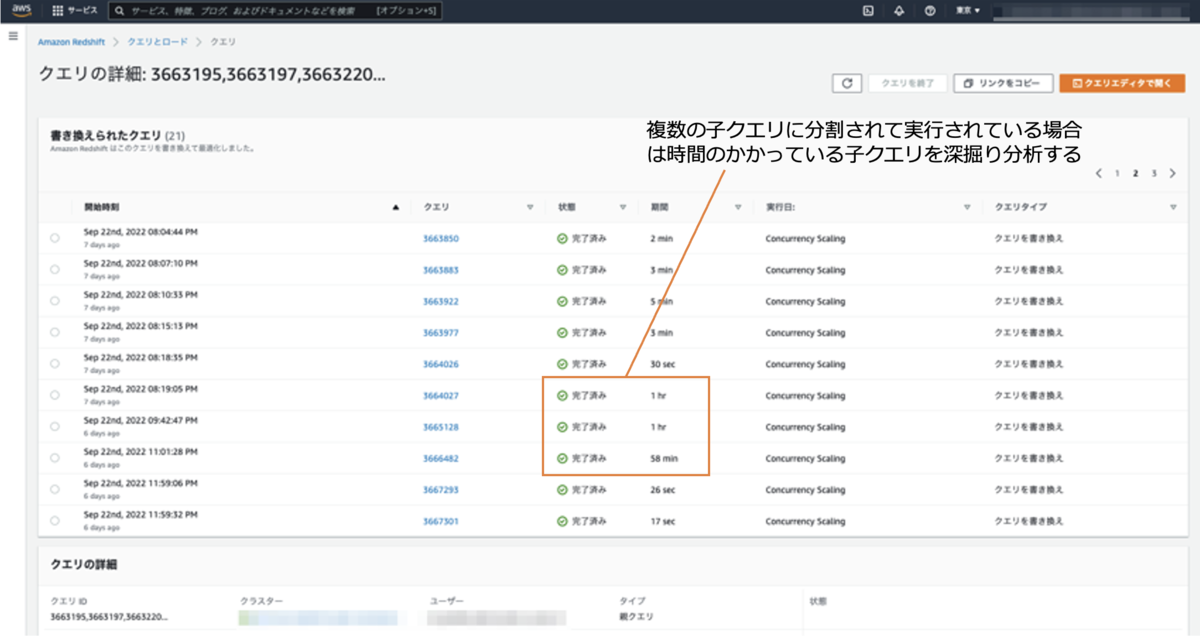
遅い子クエリを特定
Redshift でクエリを実行すると1つのクエリが複数の子クエリに分割されて実行される場合がある。その場合はどの子クエリに時間を要しているかを確認し、遅い子クエリを深掘りしてボトルネックを特定していく。
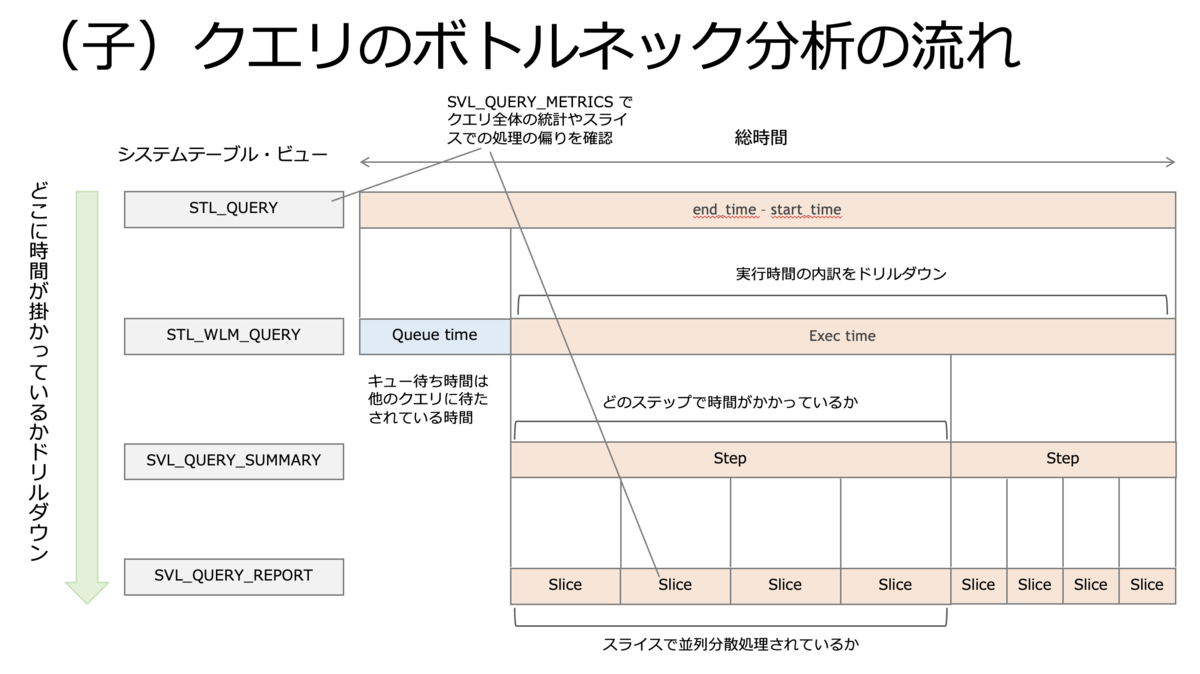
(子)クエリの中で遅い step を特定
さらに(子)クエリのどの segment で時間を要しているかを深掘りする(step 単位の実行時間は情報を取得できない)。
- SVL_QLOG
- source_query が NULL でない場合(元のクエリのIDが入る)は結果キャッシュを再利用している。
- STL_QUERY
- "endtime - starttime" でキュー待ち含む実行時間を確認する。
- starttime、endtime は "2009-06-12 11:29:19.13135" のようにマイクロ秒までの精度。
- "endtime - starttime" でキュー待ち含む実行時間を確認する。
- STL_WLM_QUERY
- total_queue_time: クエリのキュー待ち時間。待たされている時間、自クエリの実行時間ではない。
- total_exec_time: このクエリの実行時間。長い場合、チューニングを検討する。
- SVL_QUERY_SUMMARY
- maxtime が長い step がボトルネック(時間を要している箇所)。
- avgtime は各スライスでの平均実行時間、maxtime は最も遅いスライスの実行時間。
- avgtime と maxtime の差が大きい場合、均等分散せず特定のスライスの実行時間が長くなっている。
- KEY分散している場合、分散キーで均等分散していない可能性がある。値に偏りがある(ある値だけ割合が高い)場合は、分散キーを均等分散しかつ結合キーに使われている列に変更を検討する。
- workmem はソートや集計で使用されたメモリサイズ(バイト)。
- is_diskbased が t(rue) だとディスクソートされている。ストレージ書き出されたサイズは SVL_QUERY_METRICS.query_temp_blocks_to_disk で確認できる。
- is_rrscan が t だとゾーンマップを利用して範囲スキャンされている(ソートキーの効果は確認できない)。
- row = rows_pre_filter だと必要な行だけストレージから読んでいる。rows_pre_filter > rows の場合、ストレージから読んだ後にフィルタしている。rows_pre_filter - rows が大きい場合、ソートキーでIO量を削減できないか検討する。
- SVL_QUERY_METRICS
- dimension が query、segment、step ごとに表示される。query はクエリIDごとに1行でクエリ全体の統計。
- dimension=query
- query_cpu_time はクエリが使った CPU 時間。マルチコアで実行された時間の合計のため、実行時間より長くなることが普通にある。
- query_blocks_read はクエリがストレージから読んだブロック数(1ブロックのサイズは1MB)
- query_temp_blocks_to_disk は中間結果をストレージに書き出したサイズ(MB)
- return_row_count は結果セットの行数。
- dimension=segment
- segment_execution_time は各セグメントで要した時間(秒)。この時間が長いセグメントがボトルネック。
- dimension=step
- cpu_skew は全スライスの平均CPU使用量と最もCPUを消費したスライスの比率。数値が大きいと均等分散せずに特定のスライスに偏ってCPUが消費されている。
- io_skew は全スライスの平均I/O量と最もI/O量の多いスライスの比率。数値が大きいと均等分散せずに特定のスライスにI/Oが偏っている。
- scan_row_count クエリがストレージから読んだ行数
- join_row_count は結合で処理された行数、nested_loop_join_row_count はネステッドループ結合で処理された行数。
- SVL_QUERY_REPORT
- SVL_QUERY_SUMMARY をさらに詳細にスライス単位で表示する。
- start_time と end_time から step が並行実行されているか直列実行されているか判断でき、どの step がボトルネックか厳密に判断できる。
- STL_EXPLAIN
- 統計情報が収集されていない("Tables missing statistics: <テーブル名>")、直積が発生している("Nested Loop Join in the query plan - review the join predicates to avoid Cartesian products")などのメッセージが出力されている場合は確認、対応する。
- 以下のような非効率なオペレーションがないか確認する(必ずしも時間がかかっているわけではないことに留意する)
- DS_BCAST_INNER
- DS_DIST_ALL_INNER
- plannode はオペレーション、info で結合条件やフィルタ条件を確認できる。
- cost は実績ではなく「見積」のため、参考程度に見る。行が下から上に見て、数字が大きくなっているところが、ボトルネックの可能性がある。
- SVL_QUERY_SUMMARY や SVL_QUERY_REPORT の lablel と STL_EXPLAIN の plannode の紐付けの見方
関連
- クエリ調整用の診断クエリ - Amazon Redshift
- GitHub - awslabs/amazon-redshift-utils: Amazon Redshift Utils contains utilities, scripts and view which are useful in a Redshift environment
- amazon-redshift-utils/src/CloudDataWarehouseBenchmark at master · awslabs/amazon-redshift-utils · GitHub
- Amazon Redshift: Ten years of continuous reinvention - Amazon Science
- AWS re:Invent 2022 - [NEW] Amazon Redshift: 10 yrs of integration & data sharing innovation (ANT345) - YouTube