Glue Spark で出力ファイルサイズのサイズを大きくしたメモ。
サマリ
以下の2つの方法がある。
Glue カタログでデータソースの Table Properties で以下を指定する
- groupFiles: inPartition
- 入力ファイル数が 50,000 以下でもグループ化を有効にする
- groupSize: バイト数
- 出力ファイルサイズを指定する
Connection Types and Options for ETL in AWS Glue - AWS Glue
- "groupFiles": (Optional) Grouping files is turned on by default when the input contains more than 50,000 files. To turn on grouping with fewer than 50,000 files, set this parameter to "inPartition". To disable grouping when there are more than 50,000 files, set this parameter to "none".
- "groupSize": (Optional) The target group size in bytes. The default is computed based on the input data size and the size of your cluster. When there are fewer than 50,000 input files, "groupFiles" must be set to "inPartition" for this to take effect.
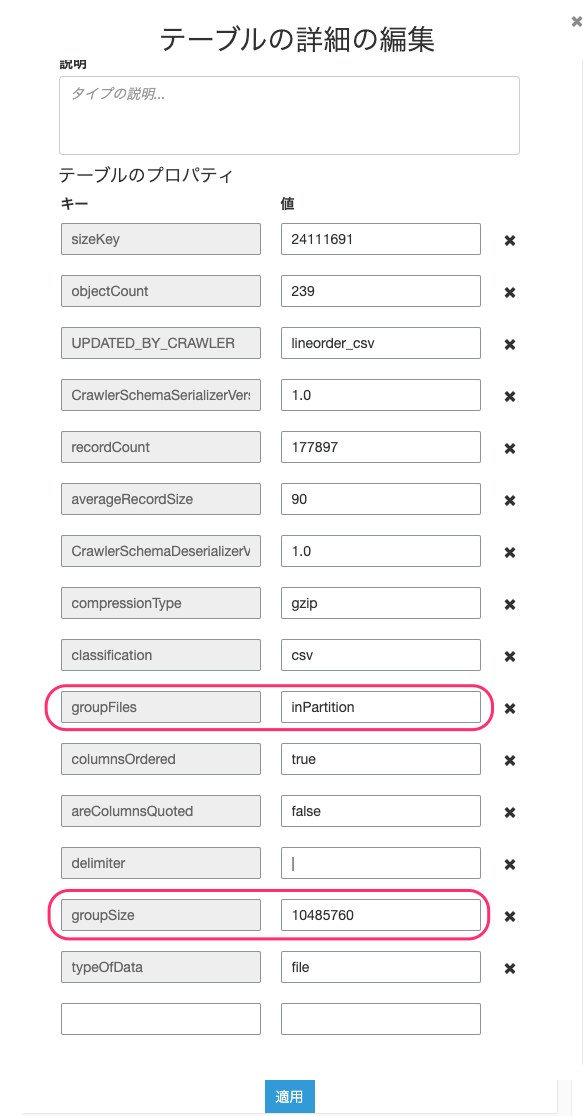
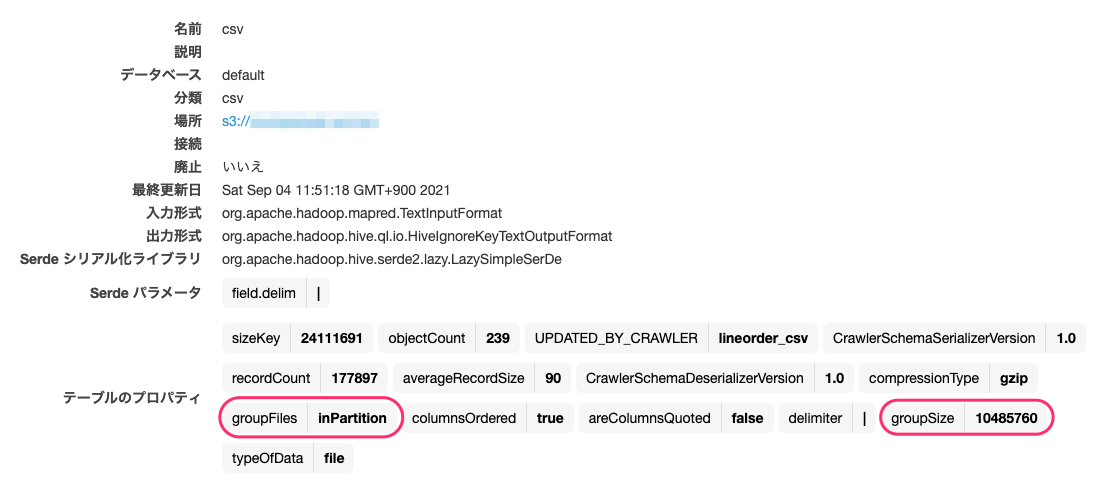
- Glue カタログを使用しない場合は以下のようにコード中に groupFiles と groupSize を記述する
datasource0 = glueContext.create_dynamic_frame_from_options( "s3", {'paths': ["s3://cm-analytics-posdata/posdata"], 'groupFiles': 'inPartition', 'groupSize': 1024 * 1024}, format="json", transformation_ctx = "datasource0")AWS Glueで多くの小さなファイルをまとめて読み込むgroupFiles/groupSize指定でパフォーマンスを改善する | DevelopersIO
検証結果
データを準備する
- サンプルデータをダウンロードする
$ aws s3 cp --recursive s3://awssampledbuswest2/ssbgz/lineorder0000_part_00.gz ./
- 解凍してファイルを小さなサイズに分割する
$ gunzip lineorder0000_part_00.gz $ split -l 2500 lineorder0000_part_00 lineorder0000_part_00_ $ ls -lh|head total 15G -rw-rw-r-- 1 ec2-user ec2-user 7.1G Sep 3 06:54 lineorder0000_part_00 -rw-rw-r-- 1 ec2-user ec2-user 248K Sep 3 07:03 lineorder0000_part_00_aa -rw-rw-r-- 1 ec2-user ec2-user 246K Sep 3 07:03 lineorder0000_part_00_ab -rw-rw-r-- 1 ec2-user ec2-user 246K Sep 3 07:03 lineorder0000_part_00_ac -rw-rw-r-- 1 ec2-user ec2-user 246K Sep 3 07:03 lineorder0000_part_00_ad -rw-rw-r-- 1 ec2-user ec2-user 246K Sep 3 07:03 lineorder0000_part_00_ae -rw-rw-r-- 1 ec2-user ec2-user 246K Sep 3 07:03 lineorder0000_part_00_af -rw-rw-r-- 1 ec2-user ec2-user 246K Sep 3 07:03 lineorder0000_part_00_ag -rw-rw-r-- 1 ec2-user ec2-user 246K Sep 3 07:03 lineorder0000_part_00_ah $ rm lineorder0000_part_00
- ファイルを圧縮して S3 にアップロードする
$ find . -type f|xargs gzip $ aws s3 mb s3://csv2parquet-test $ aws s3 cp --recursive ./ s3://csv2parquet-test/
CSV を Parquet に変換する
- 何もしないと130KB 程度の小さなファイルが出力される
$ aws s3 ls --human-readable s3://csv2parquet-test/parquet/|tail 2021-09-04 01:19:58 129.9 KiB part-00182-5c73f185-55d2-4e3b-b85e-b6634749bf61-c000.snappy.parquet 2021-09-04 01:19:58 130.0 KiB part-00183-5c73f185-55d2-4e3b-b85e-b6634749bf61-c000.snappy.parquet 2021-09-04 01:19:58 129.8 KiB part-00184-5c73f185-55d2-4e3b-b85e-b6634749bf61-c000.snappy.parquet 2021-09-04 01:19:58 129.9 KiB part-00185-5c73f185-55d2-4e3b-b85e-b6634749bf61-c000.snappy.parquet 2021-09-04 01:19:58 130.1 KiB part-00192-5c73f185-55d2-4e3b-b85e-b6634749bf61-c000.snappy.parquet 2021-09-04 01:19:58 123.1 KiB part-00195-5c73f185-55d2-4e3b-b85e-b6634749bf61-c000.snappy.parquet 2021-09-04 01:19:58 129.8 KiB part-00196-5c73f185-55d2-4e3b-b85e-b6634749bf61-c000.snappy.parquet 2021-09-04 01:19:59 129.5 KiB part-00200-5c73f185-55d2-4e3b-b85e-b6634749bf61-c000.snappy.parquet 2021-09-04 01:19:59 129.2 KiB part-00201-5c73f185-55d2-4e3b-b85e-b6634749bf61-c000.snappy.parquet 2021-09-04 01:19:59 129.7 KiB part-00206-5c73f185-55d2-4e3b-b85e-b6634749bf61-c000.snappy.parquet
- Glue カタログの Table Properties で groupFiles: inPartition、groupSize: 1024 * 1024 を指定すると、10MB で出力される
$ aws s3 ls --human-readable s3://csv2parquet-test/parquet_large/|tail 2021-09-04 03:09:07 10.2 MiB part-00278-f03ac58d-1c81-494e-84eb-c6fa9f359ea4-c000.snappy.parquet 2021-09-04 03:09:08 10.3 MiB part-00279-f03ac58d-1c81-494e-84eb-c6fa9f359ea4-c000.snappy.parquet 2021-09-04 03:09:08 10.3 MiB part-00280-f03ac58d-1c81-494e-84eb-c6fa9f359ea4-c000.snappy.parquet 2021-09-04 03:09:03 10.3 MiB part-00281-f03ac58d-1c81-494e-84eb-c6fa9f359ea4-c000.snappy.parquet 2021-09-04 03:09:03 10.3 MiB part-00282-f03ac58d-1c81-494e-84eb-c6fa9f359ea4-c000.snappy.parquet 2021-09-04 03:09:09 10.3 MiB part-00283-f03ac58d-1c81-494e-84eb-c6fa9f359ea4-c000.snappy.parquet 2021-09-04 03:09:04 10.3 MiB part-00284-f03ac58d-1c81-494e-84eb-c6fa9f359ea4-c000.snappy.parquet 2021-09-04 03:09:09 10.2 MiB part-00285-f03ac58d-1c81-494e-84eb-c6fa9f359ea4-c000.snappy.parquet 2021-09-04 03:09:09 10.2 MiB part-00286-f03ac58d-1c81-494e-84eb-c6fa9f359ea4-c000.snappy.parquet 2021-09-04 03:07:45 9.8 MiB part-00287-f03ac58d-1c81-494e-84eb-c6fa9f359ea4-c000.snappy.parquet
Glue での実装例
- PySparkのコードサンプル(Glue カタログの Table Properties を使う方式)
- 特にソースコードを変更する必要はない
import sys from awsglue.transforms import * from awsglue.utils import getResolvedOptions from pyspark.context import SparkContext from awsglue.context import GlueContext from awsglue.job import Job ## @params: [JOB_NAME] args = getResolvedOptions(sys.argv, ['JOB_NAME']) sc = SparkContext() glueContext = GlueContext(sc) spark = glueContext.spark_session job = Job(glueContext) job.init(args['JOB_NAME'], args) ## @type: DataSource ## @args: [database = "default", table_name = "csv", transformation_ctx = "datasource0"] ## @return: datasource0 ## @inputs: [] datasource0 = glueContext.create_dynamic_frame.from_catalog(database = "default", table_name = "csv", transformation_ctx = "datasource0") ## @type: ApplyMapping ## @args: [mapping = [("col0", "long", "col0", "long"), ("col1", "long", "col1", "long"), ("col2", "long", "col2", "long"), ("col3", "long", "col3", "long"), ("col4", "long", "col4", "long"), ("col5", "long", "col5", "long"), ("col6", "string", "col6", "string"), ("col7", "long", "col7", "long"), ("col8", "long", "col8", "long"), ("col9", "long", "col9", "long"), ("col10", "long", "col10", "long"), ("col11", "long", "col11", "long"), ("col12", "long", "col12", "long"), ("col13", "long", "col13", "long"), ("col14", "long", "col14", "long"), ("col15", "long", "col15", "long"), ("col16", "string", "col16", "string")], transformation_ctx = "applymapping1"] ## @return: applymapping1 ## @inputs: [frame = datasource0] applymapping1 = ApplyMapping.apply(frame = datasource0, mappings = [("col0", "long", "col0", "long"), ("col1", "long", "col1", "long"), ("col2", "long", "col2", "long"), ("col3", "long", "col3", "long"), ("col4", "long", "col4", "long"), ("col5", "long", "col5", "long"), ("col6", "string", "col6", "string"), ("col7", "long", "col7", "long"), ("col8", "long", "col8", "long"), ("col9", "long", "col9", "long"), ("col10", "long", "col10", "long"), ("col11", "long", "col11", "long"), ("col12", "long", "col12", "long"), ("col13", "long", "col13", "long"), ("col14", "long", "col14", "long"), ("col15", "long", "col15", "long"), ("col16", "string", "col16", "string")], transformation_ctx = "applymapping1") ## @type: ResolveChoice ## @args: [choice = "make_struct", transformation_ctx = "resolvechoice2"] ## @return: resolvechoice2 ## @inputs: [frame = applymapping1] resolvechoice2 = ResolveChoice.apply(frame = applymapping1, choice = "make_struct", transformation_ctx = "resolvechoice2") ## @type: DropNullFields ## @args: [transformation_ctx = "dropnullfields3"] ## @return: dropnullfields3 ## @inputs: [frame = resolvechoice2] dropnullfields3 = DropNullFields.apply(frame = resolvechoice2, transformation_ctx = "dropnullfields3") ## @type: DataSink ## @args: [connection_type = "s3", connection_options = {"path": "s3://csv2parquet-test/parquet"}, format = "parquet", transformation_ctx = "datasink4"] ## @return: datasink4 ## @inputs: [frame = dropnullfields3] datasink4 = glueContext.write_dynamic_frame.from_options(frame = dropnullfields3, connection_type = "s3", connection_options = {"path": "s3://csv2parquet-test/parquet"}, format = "parquet", transformation_ctx = "datasink4") job.commit()
- PySparkのコードサンプル(Glue カタログの Table Properties ではなく coalesce()を使う方式)
import sys from awsglue.transforms import * from awsglue.utils import getResolvedOptions from pyspark.context import SparkContext from awsglue.context import GlueContext from awsglue.job import Job ## @params: [JOB_NAME] args = getResolvedOptions(sys.argv, ['JOB_NAME']) sc = SparkContext() glueContext = GlueContext(sc) spark = glueContext.spark_session job = Job(glueContext) job.init(args['JOB_NAME'], args) ## @type: DataSource ## @args: [database = "default", table_name = "csv", transformation_ctx = "datasource0"] ## @return: datasource0 ## @inputs: [] datasource0 = glueContext.create_dynamic_frame.from_catalog(database = "default", table_name = "csv", transformation_ctx = "datasource0") ## @type: ApplyMapping ## @args: [mapping = [("col0", "long", "col0", "long"), ("col1", "long", "col1", "long"), ("col2", "long", "col2", "long"), ("col3", "long", "col3", "long"), ("col4", "long", "col4", "long"), ("col5", "long", "col5", "long"), ("col6", "string", "col6", "string"), ("col7", "long", "col7", "long"), ("col8", "long", "col8", "long"), ("col9", "long", "col9", "long"), ("col10", "long", "col10", "long"), ("col11", "long", "col11", "long"), ("col12", "long", "col12", "long"), ("col13", "long", "col13", "long"), ("col14", "long", "col14", "long"), ("col15", "long", "col15", "long"), ("col16", "string", "col16", "string")], transformation_ctx = "applymapping1"] ## @return: applymapping1 ## @inputs: [frame = datasource0] applymapping1 = ApplyMapping.apply(frame = datasource0, mappings = [("col0", "long", "col0", "long"), ("col1", "long", "col1", "long"), ("col2", "long", "col2", "long"), ("col3", "long", "col3", "long"), ("col4", "long", "col4", "long"), ("col5", "long", "col5", "long"), ("col6", "string", "col6", "string"), ("col7", "long", "col7", "long"), ("col8", "long", "col8", "long"), ("col9", "long", "col9", "long"), ("col10", "long", "col10", "long"), ("col11", "long", "col11", "long"), ("col12", "long", "col12", "long"), ("col13", "long", "col13", "long"), ("col14", "long", "col14", "long"), ("col15", "long", "col15", "long"), ("col16", "string", "col16", "string")], transformation_ctx = "applymapping1") ## @type: ResolveChoice ## @args: [choice = "make_struct", transformation_ctx = "resolvechoice2"] ## @return: resolvechoice2 ## @inputs: [frame = applymapping1] resolvechoice2 = ResolveChoice.apply(frame = applymapping1, choice = "make_struct", transformation_ctx = "resolvechoice2") ## @type: DropNullFields ## @args: [transformation_ctx = "dropnullfields3"] ## @return: dropnullfields3 ## @inputs: [frame = resolvechoice2] dropnullfields3 = DropNullFields.apply(frame = resolvechoice2, transformation_ctx = "dropnullfields3") # 現在のパーティション数を取得 curr_num_part = dropnullfields3.getNumPartitions() print(curr_num_part) # 現在のパーティション数を 100 で割って整数値に変換 output_num_part = int(curr_num_part / 100) print(output_num_part) # coalesce で現在のパーティション数 / 100 にパーティション数を減らす dynamic_frame_with_less_partitions=dropnullfields3.coalesce(output_num_part) ## @type: DataSink ## @args: [connection_type = "s3", connection_options = {"path": "s3://csv2parquet-test/parquet_large"}, format = "parquet", transformation_ctx = "datasink4"] ## @return: datasink4 ## @inputs: [frame = dropnullfields3] datasink4 = glueContext.write_dynamic_frame.from_options(frame = dynamic_frame_with_less_partitions, connection_type = "s3", connection_options = {"path": "s3://csv2parquet-test/parquet_large"}, format = "parquet", transformation_ctx = "datasink4") job.commit()