アクセスモジュールプロセッサ(AMP)-仮想プロセッサ(vproc)と呼ばれるAMPは、実際にデータを保存および取得するものです。 AMPは、Parsing Engineからデータと実行計画を受け取り、データ型の変換、集約、フィルター、並べ替えを実行し、それらに関連付けられたディスクにデータを保存します。 テーブルのレコードは、システム内のAMPに均等に分散されます。 各AMPは、データが保存されるディスクのセットに関連付けられています。 そのAMPのみがディスクからデータを読み書きできます。
Teradata-architecture - Dev Guides
How do I know how many AMPs I have in Teradata?
What is function of an amp in Teradata? – MVOrganizing
HASHAMP function in Teradata The function returns the AMP number which will hold the table row in its vdisk. This AMP will be responsible for the portion of table rows which it stores in it vdisk. It takes HASHBUCKET# as the input and returns the AMP number.
How Teradata Data Distribution Works?
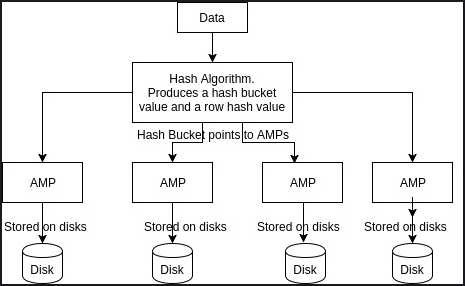
An index is a physical mechanism used to store and access the rows of a table. Indexes on tables in a relational database function much like indexes in books, they speed up information retrieval. The Teradata distributes the data based on the primary index (PI) that you create during table creation. Unique Primary Indexes (UPIs) guarantee uniform distribution of table rows across all AMP’s.When the client runs queries to insert records, Parsing engine sends the records to BYNET. The data is hashed using hash algorithm on Primary Index (PI). The hash algorithm produces hash bucket value and row hash value. Hash bucket value will be having AMP’s numbers. The BYNET sends the records to respective AMP’s based on Hashed values and AMP will intern store that in it’s associated disks.
Below picture depicts the actual data distribution in Teradata:
How Teradata Data Distribution Works on AMPs? - DWgeek.com