Amazon Redshift の WLM クエリモニタリングルールで、一時ディスクを1MB以上使っているクエリを中止してみた。
以下の例では 1MB 以一時ディスクを使用したクエリを中止している。
実行結果
[ec2-user@ip-172-31-0-222 ~]$ export LC_ALL=C [ec2-user@ip-172-31-0-222 ~]$ psql "host=redshift-cluster-2.********.ap-northeast-1.redshift.amazonaws.com user=awsuser dbname=dev port=5439" Password for user awsuser: psql (13.4, server 8.0.2) SSL connection (protocol: TLSv1.2, cipher: ECDHE-RSA-AES256-GCM-SHA384, bits: 256, compression: off) Type "help" for help. dev=# \timing Timing is on. dev=# set enable_result_cache_for_session=off; SET Time: 3.760 ms dev=# select lo_shipmode, lo_tax, lo_supplycost, lo_revenue, lo_discount, lo_orderpriority, lo_orderdate,count(*) from lineorder group by lo_shipmode, lo_tax, lo_supplycost, lo_revenue, lo_discount, lo_orderpriority, lo_orderdate order by lo_shipmode, lo_tax, lo_supplycost, lo_revenue, lo_discount, lo_orderpriority, lo_orderdate; ERROR: Query (1586) cancelled by WLM abort action of Query Monitoring Rule "cancel_heavy_temp_usage". DETAIL: ----------------------------------------------- error: Query (1586) cancelled by WLM abort action of Query Monitoring Rule "cancel_heavy_temp_usage". code: 1078 context: Query (1586) cancelled by WLM abort action of Query Monitoring Rule "cancel_heavy_temp_usage". query: 0 location: wlm_query_action.cpp:156 process: wlm [pid=15087] ----------------------------------------------- Time: 30081.170 ms (00:30.081) dev=#
設定手順
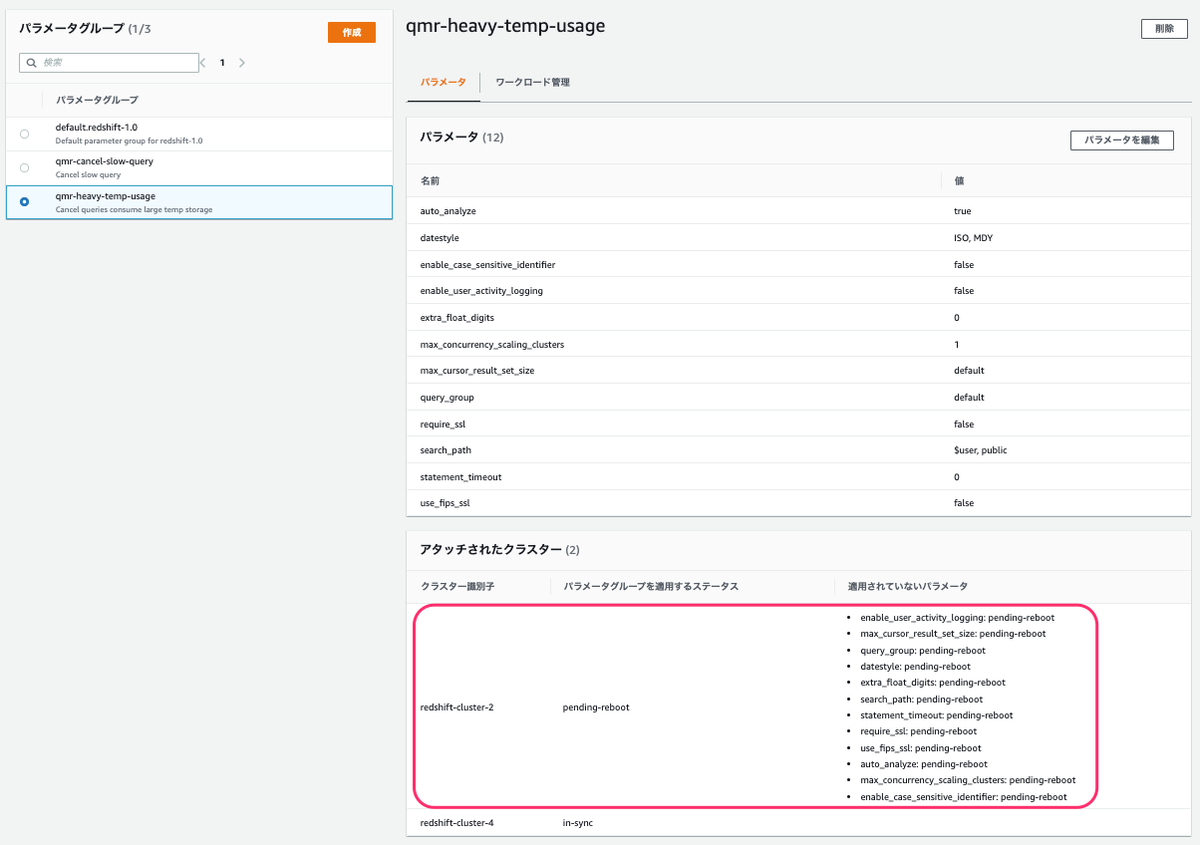
ワークロード管理でパラメータグループを作成
- マネジメントコンソールから [Amazon Redshift]-[設定]-[ワークロード管理]を選択
- [パラメータグループ]-[作成] をクリックして、パラメータグループを作成
- パラメータ名: qmr-heavy-temp-usage
- 説明: Cancel queries consume large temp storage
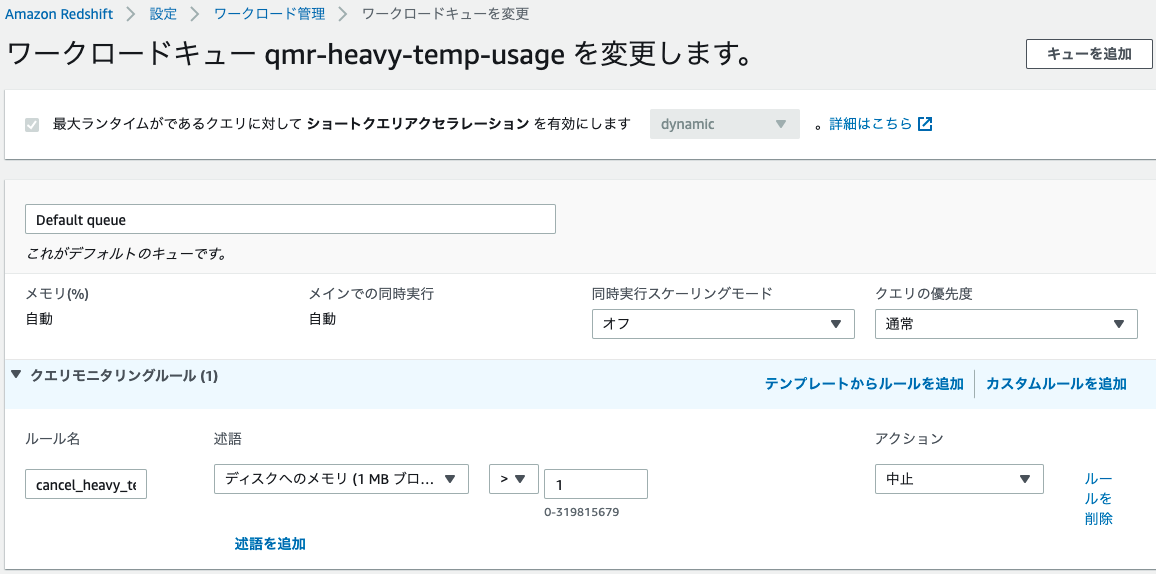
- [ワークロード管理]-[ワークロードキューを編集]をクリック
- [クエリモニタリングルール]-[カスタムルールを追加]をクリック
- ルール名: cancel_heavy_temp_usage
- 述語: ディスクへのメモリ (1 MB ブロック) > 1
- アクション: 中止
- 保存した WLM 設定パラメータの JSON 形式
[ { "auto_wlm": true, "user_group": [], "query_group": [], "name": "Default queue", "rules": [ { "rule_name": "cancel_heavy_temp_usage", "predicate": [ { "metric_name": "query_temp_blocks_to_disk", "operator": ">", "value": 1 } ], "action": "abort" } ] }, { "short_query_queue": true } ]